
Competitiveness and Innovation, Knowledge Strategy
Does genAI accelerate innovation?
I’ve invested a significant proportion of the past three years in reading, writing, discussing, and thinking about generative AI and its far-flung consequences. I had finally resolved that 2026 was the year I’d re-prioritize it (as a distraction) and let its many challenges be someone else’s problem.
Then, only a few days into the year, a Stanford-Yale research team reported what many already suspected — that “even with model- and system-level safeguards, extraction of (in-copyright) training data remains a risk for production LLMs.” They are reported to be copying and retaining Harry Potter books and other unlicensed text — thereby, to state it plainly, reselling stolen intellectual property (IP).
This complements an earlier study that found that “Generative AI model providers across the spectrum of LLMs, image, video, and music generation have obtained infringing copies of copyright protected works that were sourced from…’classic pirate sources’ such as file sharing and streaming sources.” They were found to include third party infringers like Common Crawl and LibGen.
And Stanford’s most recent Foundation Model Transparency Index (FMTI) continues to give alarmingly low scores on ‘upstream transparency and explainability’ (i.e., data sources) to most major LLMs, noting that “Significant opacity remains in areas such as…copyright status…”
Having worked in the IP protection and defense industry, I saw these as clear red flags, worthy of further investigation.
Is this a problem?
Your neighbor stops by to show you his shiny new bike. “Check out these amazing features — I’m really enjoying using it — even losing a few pounds in the process.” “Cool — how much did it cost you?” “Oh, I ‘borrowed’ it from our other neighbor. Didn’t want to bother him by asking. He won’t miss it, he hardly ever used it.”
Would you then follow your acquisitive neighbor into a discussion of the great features and benefits of ‘his’ bike? Not likely — everyone knows this doesn’t smell right. You’d be more likely to ask him if there’s any of your stuff he’s ‘borrowed.’
How is a bike like IP?
If I told you — or a few rigorous studies showed you — that it’s likely you were using stolen IP in the form of an LLM chatbot, and that there are laws against that, how would you respond? Perhaps along the lines of, “But it’s different than stealing a bike. A bike is a thing — if I have it, you no longer have it. Even if I steal IP, the original owner still has it too. It’s not the same.”
In one sense, you’d be right. Information is, technically, non-rivalrous; unlike physical things, it can literally be in two (or millions of) places at once. And, once digitized, it’s infinitely scalable.
The confusion
The scientist-philosopher Michael Polanyi famously explained that, “Owing to the ultimately tacit character of all our knowledge, we remain ever unable to say all that we know.” All knowledge is tacit — and, only when it’s expressed in conversation or writing, is it rendered explicit (as information). Polanyi calls this act of rendering articulation. (I call it ‘knowledge-to-information translation,’ but it’s pretty much the same idea.)
This distinction between knowledge and information is critical, both philosophically and from a resources management point of view. It’s also important from an economic perspective, since it’s that articulation (or translation) that establishes value worthy of being protected.
Intellectual property includes copyrights, patents, trademarks, and trade secrets. In the US, copyright law, which concerns us here, is covered under US Code, Title 17. In its nearly 500 pages, its sole focus remains protecting “original works of authorship fixed in any tangible medium of expression, now known or later developed, from which they can be perceived, reproduced, or otherwise communicated, either directly or with the aid of a machine or device.” (Section 102.) Such protection is not extended (by this law) to any “idea, procedure, process, system, method of operation, concept, principle, or discovery.”
This law specifies that the right of IP ownership goes to the articulating agent — the person who first ‘fixed’ it in a tangible medium — for example, by writing it down. And, unlike the information itself, that ownership is non-scalable and rivalrous. If I wrote it, it’s mine alone to use as I please — unless and until I sell or license it to someone else for their use. Information scales; ownership of information does not.
Please forgive my focus on US law and practice. Many other countries have their own copyright laws, which may differ in key elements. These are generally coordinated through an international treaty, the Geneva Convention.
The work of articulation
Anyone who writes seriously knows that it’s hard. The spelling, grammar, vocabulary, and syntax are hard enough. But the real work is the thinking part — what do I want to say, to whom, what do they know already, what effect do I intend to convey, and so on? This applies by analogy to any creative effort.
Ideas are a dollar a dozen — even promising ones. But ones that can be captured tangibly and used later are considerably more rare — and it’s that scarcity that generates economic value. This scales up to our ‘epistemic economy,’ which is largely credited with having improved human life dramatically during the past 500 years.
Innovation is produced by innovators
Innovation is not a force of nature, like the tides or winds. It is the aggregate result of the combined efforts, over time, of innovators. Intellectual properties are man-made artifacts — products of human thought and endeavor.
Innovation is the spark of discovery and invention that drives progress in science (knowledge) and technology (the application of knowledge). We protect and nurture that spark by protecting the conditions that foster innovation — and that primarily means protecting and nurturing innovators. When incentives to innovation are diluted or removed, innovation withers and eventually dies.
The US Constitution agrees
I regard the US Constitution as, on the whole, a brilliant blueprint of societal engineering. Article I, Section 8, paragraph 8 grants Congress the power “to promote the progress of science and useful arts by securing for limited times to authors and inventors the exclusive right to their respective writings and discoveries.”
Anything in the Constitution appears there only after significant deliberation and debate. Our republic’s framers clearly viewed science and ‘useful arts’ as critical for our democracy, and progress therein (that is, innovation) as essential. And their single named way of protecting that innovation was to protect the rights of the innovators (authors and inventors) who produce it. And to specify that such rights are exclusive — meaning that they are granted to no one other than the innovator.
Innovators are human
In our age when technology-generated ‘authorship’ is rampant, its legal status is a key consideration. The US Copyright Office’s position is that, “It is well-established that copyright can protect only material that is the product of human creativity. Most fundamentally, the term ‘author,’ which is used in both the Constitution and the Copyright Act, excludes non-humans.” The courts have, so far, generally held that prompting does not constitute authorship.
This means that, for example, AI-generated content, for example computer code, is likely not copyright-protected. If an organization’s IP value is at issue, for example in an acquisition, this is a key consideration.
Private property
The government’s duty in protecting private property is long-established. During the first-century BCE Roman Republic, the statesman-philosopher Cicero said, “Everyone shall have what belongs to him and…private citizens [shall] suffer no invasion of their property rights by act of the state.” (I’m going to have to plead ignorant of how this works in socialist societies. Please jump in if you know about this.)
So if you’re an ‘agent of articulation’ — an innovator, a creator, an author or inventor — the government sees you and your work as valuable and protects you and your innovations. Right?
For the most part, yes. But technology typically races ahead of government’s ability to understand it and deal with it equitably. The copyright laws are amended often, usually in response to such developments.
But there’s invariably a lag before laws catch up; and such lags invite vitriolic debates and lawsuits. Two examples come from the recorded music industry, often a bellwether for issues that go on to affect other creative areas.
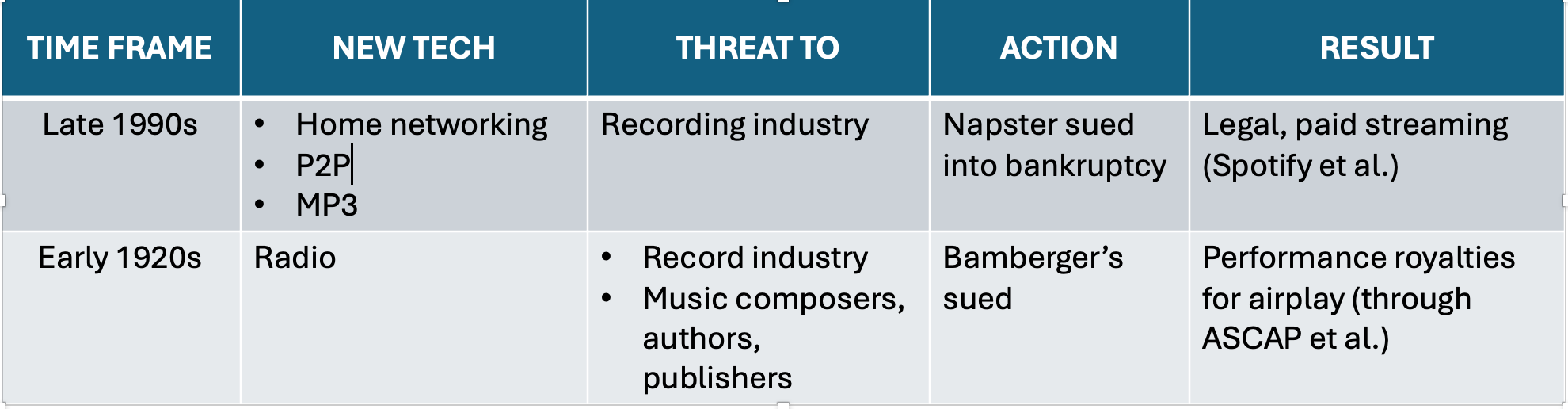
Free music — 1990s edition
Some of you may remember this. By the 1990s, many computers, even those at home, had become networked. And a file compression protocol called MP3 was introduced, that enabled audio files to be compressed to about ten percent of their original size, with little noticeable loss of fidelity.
Entrepreneurs jumped on these developments to form peer-to-peer (P2P) networks Napster, Limewire, and others — file sharing services whose customer value proposition was ‘free music’ — since it depended on home users sharing with other home users, with no middleman.
Sales of legitimate recorded music (then tapes, CDs, and vinyl), plummeted — and experts were forecasting the death of the industry. Several labels fought back, sued, and eventually put the pirates out of business. (Napster has since regrouped with a different business model.)
The streaming technology itself was the wave of the future — but the legal and financial scaffolding around it needed to be developed. Legitimate, licensed streaming became an industry, pioneered by Spotify, followed by Apple, Tidal and others. The recording industry’s fortunes reversed; it now enjoys its highest revenues ever.
Free music — 1920s edition
Few people here remember a strikingly similar case from a century ago. In the 1920s, when commercial radio was new, musical programming was a staple — with musicians coming physically into the studio and playing live on the air. Radio programmers soon found that this was expensive and unwieldy — and that a much greater volume and variety of programming could be had by playing back pre-recorded musical segments: records.
The radio disk jockey was born. With music now coming across the airwaves free, the listener no longer needed to buy records — a benefit that later in the decade became even more valuable, when the Great Depression strained household budgets.
Of course, the station still had to buy records. They generated funds to do this by advertising. Most ads came in the form of program sponsorships, e.g., the “King Biscuit Flour Hour.”
Whose ox got gored? Music composers and authors (lyricists) among others, whose income streams had only recently shifted from sales of sheet music to ‘mechanical royalties’ paid on the sales of records.
They fought back. In a landmark 1923 case, these composers and authors, along with their publishers, sued a major sponsor that ran its own ‘captive’ radio station— Bamberger’s Department Store in Newark, NJ — and won (for all of us) the right to receive performance royalties on the airplay of their work.
These payments were to be administered by the new performing rights organizations (PROs), whose best-known examples are the American Society of Composers, Authors, and Publishers (ASCAP) and Broadcast Music, Inc. (BMI.) I’m a member of the former, which helps explain my admittedly obsessive interest in this issue.
Value proximity
Notice the pattern here? (And I haven’t mentioned digital sampling, a similar case with a similar outcome.) In both these cases seven decades apart, purveyors of a new technology tried to jump to the head of the value chain, economically threatening its other parts. And failed short term — succeeding only later when they finally acknowledged the rights of content creators.
Both cases illustrate a general principle I call value proximity: the closer (in the value chain) to the consumer sits a piece of information information, the greater the perceived value of that information.
‘Free music’ was a short-lived illusion enabled by a new and ‘mysterious’ technology; but the ownership of content creators and owners eventually prevailed. Will the same principles now be held to apply to other content — digital text, images, and music? See you in court!
I confess
Language models are interesting and fun. And potentially useful, though most of us are still experimenting. Given my background in psychology, organizational intelligence, and statistics and data analysis, and my fascination with words, I should be a proverbial duck playing in water.
As it stands, I’m sorry, but I can’t bring myself to do it in any rigorous way. To do so, I’d have to convince myself I don’t know that their value model depends on ‘redefining,’ or even stealing, IP — something I’ve spent a good chuck of my career trying to mitigate. It ‘smells’ too much like my apocryphal neighbor’s bicycle thievery — making me, in effect, a very small accessory to a very large crime.
When confronted with that inconvenient truth, the AI industry has offered a cascading series of obfuscations and implausible denials (first “we didn’t scrape,” then “we scraped, but it’s allowable as fair use,” then “it’s publicly available data, therefore fair game,” then “how we source our data is a trade secret — and none of your business.”) It’s not necessarily that they’re malevolent or morally naive people — for them, it’s existential. (As it likewise is with creators.) If the genAI industry paid for its ‘raw materials’ (like the rest of us do), it would substantially transform — or even upend — the industry as we know it. (None other than Sam Altman, who would know, has warned of this.)
As I preach, so do I practice — I don’t use genAI, except to test it its potential usefulness. I wouldn’t presume to tell you what to do (unless perhaps you were my client — and even then, I’d be recommending). And I don’t intend to virtue signal or come off as holier-than-thou. Each of the eight billion of us on the planet has to make his or her own decisions in life.
But, as a ‘card-carrying’ systems thinker, I’m aware that our decisions, as small as each one is, scale up into what become economic forces and trends. So I weigh my own choices against a backdrop of those trends and their potential consequences to our epistemic ecosystem.
Is generative AI digital slavery?
Generative AI models are trained, at least in part, by robotically appropriating (‘scraping’) vast quantities of ‘publicly available’ (but not public domain) information from the internet — with neither the permission of, nor payment to, its producers and/or owners. By blurring the rights of creative ownership, it effectively bends the value of the ‘ingested’ information artifact toward zero. This removes incentives for creativity and innovation. Creative people have bills to pay, and, rather than submit to some form of under-compensated labor — less politely stated, digital slavery — they will over time migrate toward other ways of earning a living. And the pipeline of useful invention will eventually run dry.
Here’s how this works over time:
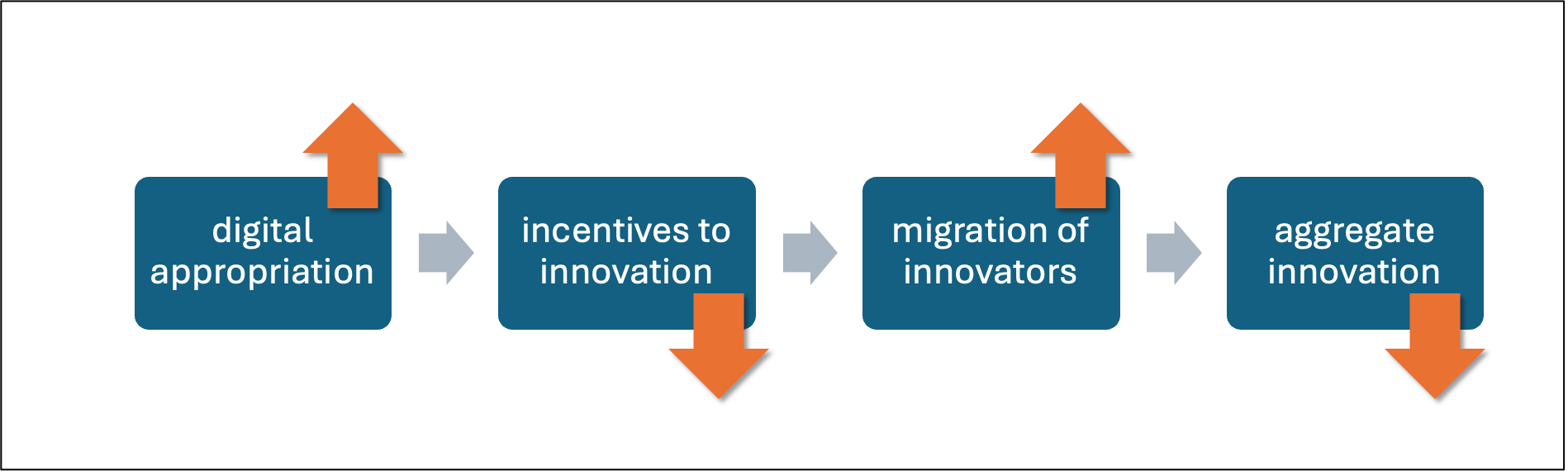
Figure 1: Incentives to innovation
This system dynamics view suggests that the overall net effect is to suppress, rather than to promote, innovation.
The way forward
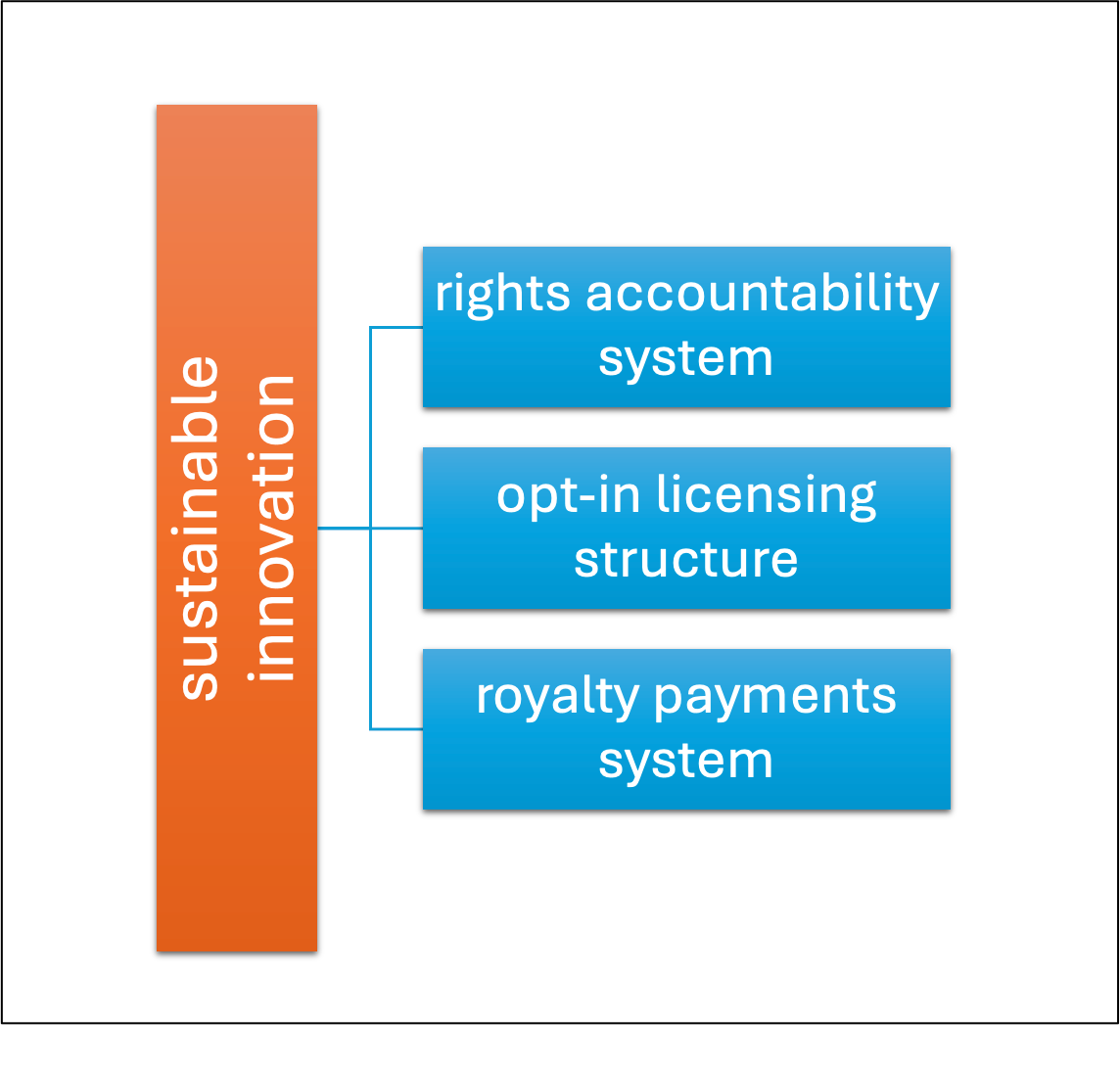
Figure 2: A conceptual model for sustainable innovation
There is an answer — just as there was in the historical examples above. And it’s likely the a similar answer, containing three essential elements: (1) an IP rights accountability system, (2) an opt-in licensing structure, (3) a royalty payments system.
The Stanford-Yale study may accelerate the nearing-100 outstanding lawsuits and spur lawmakers to protect innovation by protecting innovators. New laws are not needed for genAI; in the US, copyright law has been continually revised as new technologies emerge. That said, clarifications for digital copying and reuse by language models for text (and diffusion models for images) are urgently needed.
Realizing this, the AI industry has mounted its own global effort to ‘modernize’ the IP laws — in ways that benefit them. This is done in the name of removing impediments to innovation. How ironic that, if successful, they could have exactly the opposite effect.
We have the means at hand to resolve this. As it is, we’re spinning a lot of precious resources — time, effort, attention, and money — on questions of is this, or is this not, IP rights infringement? The Stanford-Yale study offers further proof that it is. The AI industry’s refusal to openly acknowledge and solve this issue represents a significant roadblock.
Let’s remove this barrier and begin to accelerate toward a future where technology respects and reinforces the rights of innovators. Let’s do this now — so we can move on to other important concerns: do these technologies work, are they reliable, do they add value, where, how, and so on.
True innovation is the lifeblood of our economy and society. Let’s cherish and nourish it — not stifle it.
The future
Data ownership is a — if not the — defining issue of our time. The future health and sustainability of our information-based economy depends on getting this right.
I predict the following:
- lawsuits from content creators and owners will continue
- innovators will become increasingly organized and politically active
- the laws and courts will stumble along — but will not likely approach the speeds of tech development
- licensing agreements will accelerate — as has already happened with text (for example, Open AI/News Corp), video (OpenAI/Disney), music (Udio/Warners and UMG)
- paywalls and better technology-based IP protections will arise
- the ‘all-you-can-steal’ window of the early 2020s will prove to have been a one-time anomaly that is now closing
- its closing will test the already-precarious financial viability of the genAI industry
- digital governance on the buyer side will become more dynamic — and principles-based, i.e., technology agnostic
- genAI customers (especially at the enterprise level) will rightfully demand greater transparency and documented arm’s-length assurances of ‘clean data sourcing’
SOURCES
- Ahmed et al. (2026) “Extracting books from production language models” – the ‘Stanford-Yale study’
- Stanford Center for Research on Foundations Models, HAI Index Report 2025, Section 3.8
- Danish Rights Alliance, Report on pirated content used in the training of generative AI, March 2025
- Polanyi, Personal Knowledge (1958), Chapter 5 “Articulation,” Section 5
- Cicero, On Duties, Book II.XXI
- Powell, The Value of Knowledge (2020), Sections 1.5.2, 2.4.4, 6.6.1
- US Copyright Office, Copyright Registration Guidance: Works Containing Material Generated by Artificial Intelligence – March 2023
- Samuels (2000), The Illustrated Story of Copyright
- Copyright Law of the United States, Title 17 of the United States Code (December 2024)
I’ve just started a timely book Who owns this sentence: a history of copyrights and wrongs by a literature professor and a lawyer.
Apologies for the long read — and I’ve just scratched the surface of this complex, important, and fast-moving issue. Please DM me (here or on LinkedIn) if you have questions or seek further details.
These are solely my opinions. They do not represent legal advice, for which you should retain counsel. Nor do they necessarily reflect the views of The Conference Board or others of my clients.
Image and text-based generative AI systems are clever, spectacular, and amusing, and have commanded a huge share of our collective attention during the past three years. And they may have lasting economic value, the jury is still out. However, to a yet-to-be-determined extent, their core value model depends on selling IP that may not rightfully be theirs to sell. If this is held to be true, they’re at odds with US laws, and even the Constitution. And they’re on shaky ground — ethically, legally, financially, even existentially.
Recent Comments
on PARALLEL WORLDS 3: Conflicts and Gaps: “Thanks, Henry, I agree. Language is indeed physical — muscles and other tissues moving, thereby producing sound waves. But –…” May 18, 12:31
on PARALLEL WORLDS 3: Conflicts and Gaps: “Love that! 🙂 Additional to that: Language at times can also be very ‚physical‘ within a neuronal network. [Emotion] :-)…” May 18, 09:41
on Enterprise Knowledge: What is it?: “This insightful analogy beautifully highlights the multifaceted nature of Knowledge Management. The “whole elephant” perspective underscores the need for cohesive…” Dec 30, 05:52
Comments RSS Feed