
DATA: They’re people
 This headline in a recent Wall Street Journal (June 5th) is one that could cause concern only for a true data geek like me. The gist of the article is that, because of staff shortages at the US Bureau of Labor Statistics, these monthly data can no longer be trusted as fully reliable.
This headline in a recent Wall Street Journal (June 5th) is one that could cause concern only for a true data geek like me. The gist of the article is that, because of staff shortages at the US Bureau of Labor Statistics, these monthly data can no longer be trusted as fully reliable.
Inflation numbers are critical to the US economy, both as metrics of health, and as triggers to action (for example, adjustments to interest rates.) The author reminds us that these data so vital to our economy do not appear magically — they are the results of market-basket surveys of prices at a range of retail outlets. Such surveys may involve visits to retail stores in various US cities by human ‘enumerators.’
Of course, there are techniques to mask such shortfalls. Interpolations and other forms of statistical data synthesis can be used to fill in the gaps — at least, for appearances’ sake. But synthetic data by nature have an incrementally more distant relationship with reality than do fresh, organic collected data.
Data are human
My point is simple: that each data element is the result of human effort — often by more than one person. Even where the collection is automated, the automation algorithm must be designed and coded, the result monitored for accuracy, and the aggregation and analysis conducted.
“Data” is the plural of the Latin “datum” (an observation, recorded). Too often its scale — its bigness — leads us to to think of data as some abstraction that exists with a life of its own — and that grows ‘out there,’ ripe for the harvesting. But in fact each datum is the work of a human micro-process — the recording of some observed phenomenon (the price of goods in this case).
And because it is the result of human labor, each datum therefore has an economic aspect as an input — the cost of producing or collecting it. All data are human — and are economic. Absent humans, there are no data; and absent payment, there are no humans.
Data have consequences
Data, of course, matter on the output side, too — they can have profound impacts on our lives. One’s date of birth, one’s SAT score or GPA, one’s credit score — all these data carry major life impacts.
Of course, it’s not the data per se, but what the data measure that has the true impact. That said, data can take on an authority of their own — as you’ll know if, for example, you’ve ever had to contest an inaccurate credit score. So the quality of data is also critically important.
Getting behind the numbers
Data are people. It was a professional experience that first brought this home to me. I was working as a econometric modeler for KPMG, building an interactive model of the New York State economy’s sales tax base. Though we were among the first people at the Firm to be using online data, at that time we were still getting most of our important data via hard-copy publication. (The was long before the internet, when PCs in business were still rare. Technology has changed — but most of the ‘laws of information’ still apply.)
A key data element in our research was Personal Consumption Expenditures (PCE), a huge data set that measures how much we in the US spend on various retail items. My manager at the time was the prominent business economist Don Welsch — who, in addition to being a great mentor, became a friend and benefactor.
One day, Don suggested to me to get my head out of the data book and pay a visit to the person who wrote it. I was astonished — I didn’t know you could do that.
‘Training’ for data
I made a couple of calls, then hopped an Amtrak down to the Commerce Department in DC to meet with the person behind the numbers. Most people, I’ve found, love to discuss their work — and are grateful to find out how useful it is (and how it is useful) to others. This cordial and competent civil servant was no exception, and was generous with her time and recommendations.
As you might guess, two major benefits resulted. First, I understood much more about where the numbers came from, what they represented, which ones here ‘firmer’ versus estimates, and so so. But, more importantly, I had made a personal connection. So when, later in the project, I needed some clarification, I had an open line — rather than merely being ‘some guy calling from KPMG.’
The project was successful — and my paper describing it (co-authored with Don) was published in an academic journal of regional economics.
My secret sauce
I never again took data for granted. This later gave me an edge up in the field of strategic intelligence — the ‘secret sauce of my success’ was that I always dove in behind the numbers. I never saw a published article as an end, an ’answer’ — I saw it as a beginning, a lead into a conversation I might have with its author or other subject matter expert.
Another thing I learned along the way is that, in addition to responding positively to attention to their work, authors typically have notes several times deeper than whatever ended up being published in edited form.
“There’s almost nothing available…”
My most fascinating job, before launching independent, was working as a strategic research director at Find/SVP, part of a global research network. We had a ‘quick search’ group whose job it was to do complex online searches (of Lexis-Nexis, for example) and to report the results to the client. (Again, this was before the internet was available commercially.)
The quick search analyst’s job was to simultaneously advise a more senior person (like me) to investigate whether more bespoke (and expensive) work would benefit the client. Most often, they were happy with the ‘quick and dirty’ answer.
But not always…
And that’s where things got interesting; when the stakes and risks got higher, quick and dirty was no longer sufficient. One case involved a major credit card’s questions about payday lending, a specialized consumer credit market. Our analyst, one of the most brilliant and thorough in the industry, reported to the client — and to me — that there was exactly one short article on this potential market opportunity.
For some clients and some situations, that would have sufficed. But here, I soon learned, they had previously budgeted millions of dollars to gain access to this market — and wanted a reality check to see what risks and challenges they could be facing.
I began with that one brief article. I tracked down the author, a college economics professor — and found him delighted to discuss that article — as well his major findings from a not-yet-published research paper commissioned by a government entity. This single conversation opened a new world for me.
Out of that, I developed and led a team that executed a multi-modal process involving complex secondary research, primary interviews, competitive analysis — the works. Our research concluded that this was, for various reasons, not an attractive market at that time. The client withdrew their planned entry — saving them lots of money, effort, and reputational capital.
KVC redux
My Knowledge Value Chain is more widely used than any single other of my ideas. I’ve lectured on it around the world and applied it in many situations. I recently met with one of the earliest sponsors of my work, who inquired when I was going to bring out the next iteration of the book. (The current one is the fourth edition, from 2014.)
So I’ve been thinking about what I would clarify, add, or change in a future iteration. Only minor things, I’m pleased to report. For one, I would emphasize, at the beginning of the chain where I discuss collecting data, that even before that is people — human attention, human decisions, human labor, human economics. It’s implied already, but now deserves renewed emphasis.
Data abstractions
The rise of generative AI, and ‘big data’ before that, have tended to gloss over this immutable fact. While everyone knows that ‘garbage in, means garbage out’ — fewer realize that knowing the human source is a key to data quality.
But what about ‘automatic’ collections — Google Maps cars driving around with cameras on them, spiders crawling and scraping the internet, and so on? None of this is magic or divine intervention — it’s all determined by human decisions as to what to collect, how to process it, how to present it, and so on. Every single last datum; there is no exception.
It’s easy to lose sight of this in the vast oceans of data we all continually navigate. Data are people. When data become abstract, people become abstract. When people become abstract, we have lost our way.
As I preach, so do I practice. In seeking ‘truth and light,’ I always reach for the human source. When Wikipedia first was introduced, we did not use it for client research — because it contained few citations. It now has many — and we use it all the time, assured that we can refer to the original sources when needed.
What is true?
Today we hear concerning questions about how to determine what is true, the value of truth — and even what truth is. Though this seems paradoxical in our age of information, it’s actually predictable — as we get overloaded and confused by the firehoses of data continually rushing at each of us.
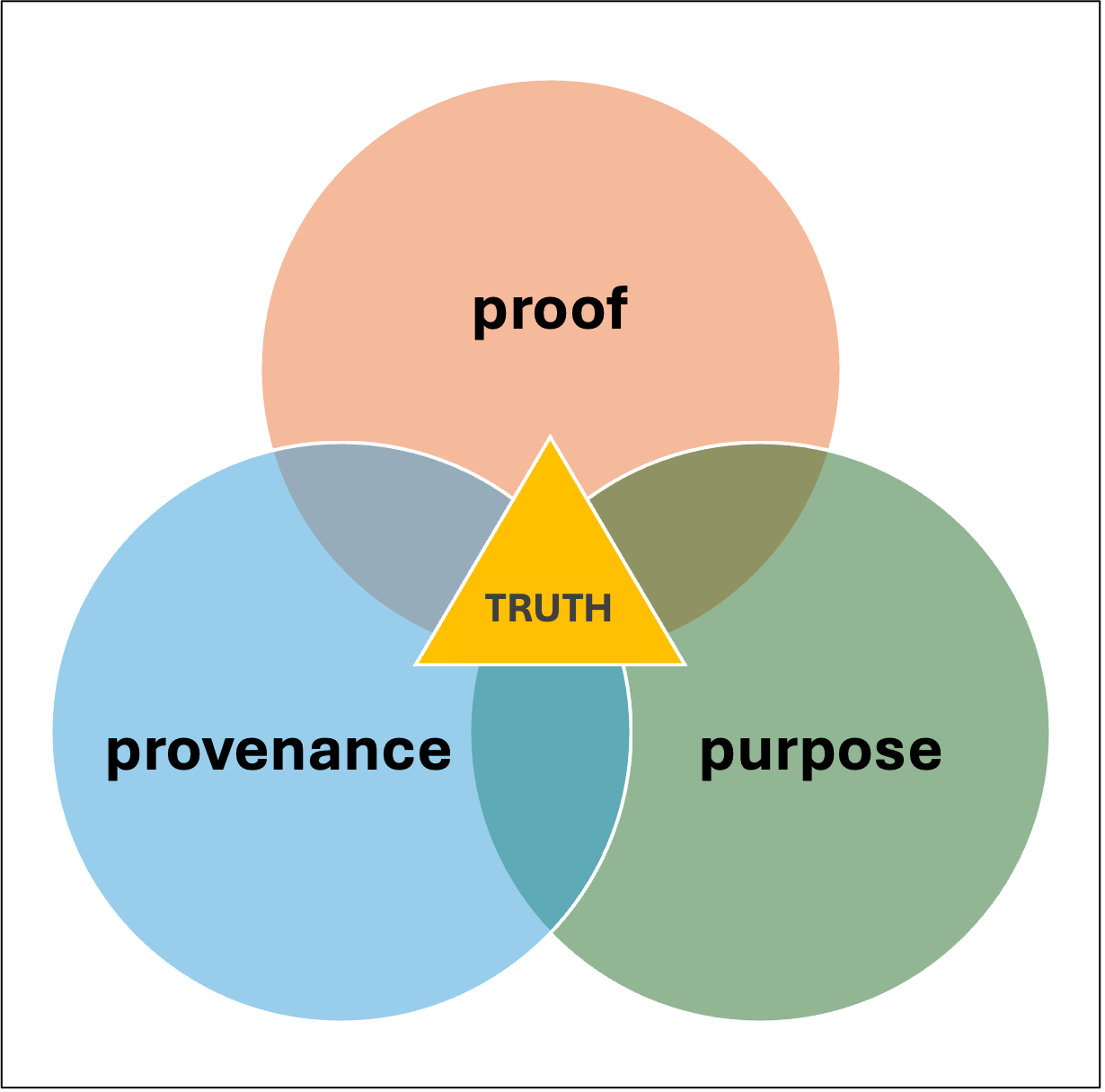
Simple Truth Test
In my two decades’ work as a strategic intelligence agent, one role I often played for my clients was to vet and verify data — to filter the signal from the noise. The three-way test of truth I used (based on my studies of cognitive psychology and intelligence methods, as well as my case experience) was simple: proof – provenance – purpose.
- Proof — Do we have at least one additional independent evidence-based source that confirms the information?
- Provenance — What is the source, and can we trust that source?
- Purpose — Why does this information show up here, at this time? (Since, as mentioned, data don’t grow on trees.) Who benefits, and how?
What about genAI?
The human-datum connection is critical for each of these tests. If we break that bond, we risk jeopardizing all three elements of our truth test. And breaking that bond seems a key element in how LLM chatbots work. It’s a serious bug — when I cannot reliably determine who produced a piece of information, most of its value to me is lost. I have no way to check or verify it — it’s little more than random words on a page.
What’s worse is that some view this rupture as a feature — that we have somehow liberated data from the inherent limitations of humanity. ‘Trans-humanism’ — a nicer-sounding wrapper than the de-humanization it represents — is becoming a semi-formal ideology that some people are taking seriously.
As a former psychologist, I fully realize that where there are humans, there are human problems. (To wit, humans sometimes make mistakes; humans sometimes call in sick; humans sometimes take unwarranted shortcuts; humans are biased and easily distracted; and so on.) So it is tempting to want to eliminate them from the loop.
But, once again, all data are human at their root. We can neither escape this, nor hide it by pretending ‘it’s the algorithm.’ In fact, it’s data (in the form of words, images, and numbers) that make us human — and that enable us to coordinate, cooperate, and generally have social and organizational lives. Absent these, we’d still be foraging for food alongside the higher apes.
Call me a humanist
When I graduated from Yale (the first of two times), we had a two-stage graduation — one with our undergraduate class of about 1200 people and all the graduate and professional students from the university’s other schools. Impressive for sure, but impersonal.
Following this was a much smaller gathering of around 100 new graduates, in our residential college ‘where everybody knew your name.’ My master (as they were then called) was JP Trinkaus, a noted biologist and (it turns out) keen observer of personalities. As he handed me my diploma, he thanked me for being a humanist. Coming from a well-regarded scientist to me, a ‘recovering’ pre-medical student, I wasn’t sure at the time if his comment was sincere — or back-handedly sarcastic.
All these decades later, I now know — and accept — what he sensed. Trink, wherever you are, thank you for that insight! “Proudly human,” I’ll fly that flag anytime. At the risk of overly dramatizing, it’s something I’ll fight for — a hill I would die on.
Can we love data — respect, even revere data — and remain human? I see no inherent contradiction — only temporal, man-made challenges. I mean to rewatch the film Soylent Green, which inspired my title.
Recent Comments
on PARALLEL WORLDS 3: Conflicts and Gaps: “Thanks, Henry, I agree. Language is indeed physical — muscles and other tissues moving, thereby producing sound waves. But –…” May 18, 12:31
on PARALLEL WORLDS 3: Conflicts and Gaps: “Love that! 🙂 Additional to that: Language at times can also be very ‚physical‘ within a neuronal network. [Emotion] :-)…” May 18, 09:41
on Enterprise Knowledge: What is it?: “This insightful analogy beautifully highlights the multifaceted nature of Knowledge Management. The “whole elephant” perspective underscores the need for cohesive…” Dec 30, 05:52
Comments RSS Feed